
Table of Contents
- Introduction
- Why is Survey Fraud Detection Important?
- Understanding the Role of Data Cleaning in Survey Fraud Detection
- What are the Common Types of Survey Fraud and the Challenges in Detecting Them?
- Key Steps in Data Cleaning for Survey Fraud Detection
- Essential Tools and Techniques for Data Cleaning
- Automation in Data Cleaning: Taking Efficiency to New Heights
- Impact of Data Cleaning on Survey Results
- Real-Life Success Stories: Data Cleaning in Action
- Why Data Cleaning is Crucial for Accurate Survey Results
Introduction
Survey fraud detection helps identify and remove low-quality or fraudulent survey responses. It’s like being a detective, finding patterns and inconsistencies that point to dishonest submissions.
Why is Survey Fraud Detection Important?
- It ensures your survey results are accurate
- Protects your decision-making processes
- Preserves your organizational reputation
- Saves resources by focusing on reliable data
As noted by Wang and Strong (1996), “Data quality encompasses various dimensions beyond accuracy, including consistency and completeness, which are crucial for reliable survey results.”
Understanding the Role of Data Cleaning in Survey Fraud Detection
What is Data Cleaning?
What is Data Cleaning? Data cleaning, or scrubbing, is a crucial part of survey analysis and fraud detection. According to Biemer and Lyberg (2003), “Data cleaning turns raw survey data into reliable insights by fixing errors and inconsistencies.”
Data cleaning involves identifying and correcting errors, inconsistencies, and inaccuracies in datasets. For survey data, this includes:
- Removing duplicate responses
- Handling missing values
- Correcting formatting issues
- Standardizing data entries
- Addressing outliers
How Does Data Cleaning Help Fraud Detection?
According to Schreiner, Riedl, and Roithmayr (2020), “Effective data cleaning removes noise, enhancing fraud detection by making patterns and anomalies easier to spot.” It establishes a clear baseline for anomaly detection and improves the overall efficiency of fraud detection processes by:
- Removing noise that could mask fraudulent patterns
- Enhancing pattern recognition capabilities
- Facilitating cross-referencing with other data sources
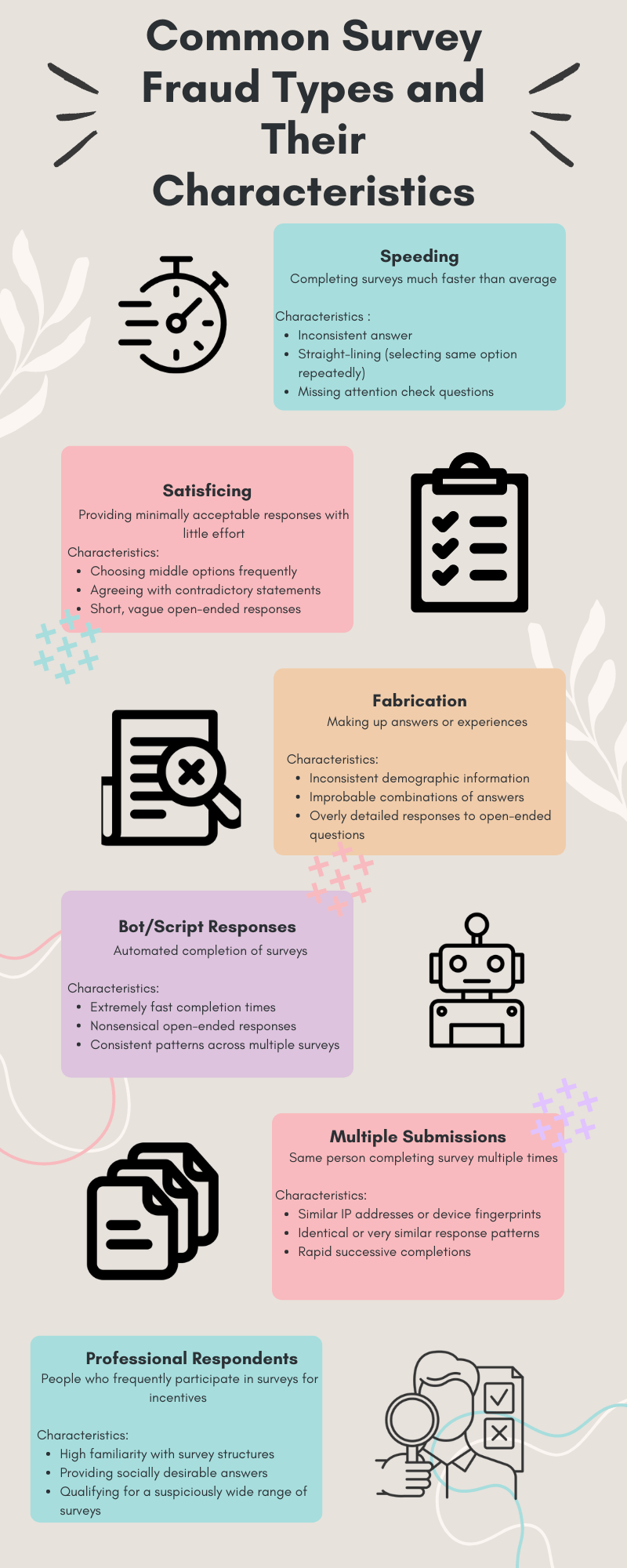
What are the Common Types of Survey Fraud and the Challenges in Detecting Them?
Here are some common types of fraud:
- Bot and automated responses: Generated by scripts or automated systems.
- Duplicate submissions: Respondents submitting multiple entries to skew results.
- False or random responses: Participants providing inaccurate or random answers, often to claim incentives.
Challenges in detecting survey fraud include the complexity and volume of survey data, increasingly subtle fraudulent patterns, and evolving fraud techniques (Redmiles & Mazurek, 2019).
Key Steps in Data Cleaning for Survey Fraud Detection
Removing Duplicate Responses
Duplicate entries can distort your survey data. Tools like Excel macros or more advanced software help identify and remove exact or near-duplicate entries. This ensures each response reflects unique feedback. As noted by Wang and Strong (1996), removing duplicates reduces potential skewing of results.
Handling Missing or Incomplete Data
Incomplete data can distort analysis, but outright removal isn’t always the best solution. Techniques like multiple imputation or predictive models can fill gaps, allowing valuable responses to be salvaged (Biemer & Lyberg, 2003).
Normalizing and Standardizing Data
Open-ended responses often contain inconsistencies. Standardizing data formats ensures consistency across the board. According to Hill and Lewicki (2006), “Normalization is vital to improve the clarity of data and facilitate better comparisons.”
Essential Tools and Techniques for Data Cleaning
- Spreadsheet Software (Excel, Google Sheets): These tools are ideal for small to medium-sized datasets. Functions like identifying duplicates and removing empty fields can be automated for efficiency (Redmiles & Mazurek, 2019).
- Statistical Software (R, SPSS): For more advanced cleaning, R and SPSS provide robust tools for statistical analysis. These can handle tasks like pattern recognition and anomaly detection, especially in larger datasets (Wang & Strong, 1996).
- Programming Languages (Python with pandas): Python, especially with the pandas library, is a go-to for automating processes like deduplication and outlier detection in large datasets. As noted by Schreiner, Riedl, and Roithmayr (2020), “Python’s integration with machine learning algorithms adds another layer of fraud detection.”
- Dedicated Data Cleaning Tools (OpenRefine, Trifacta): Specialized tools like OpenRefine and Trifacta provide advanced platforms for cleaning. These are particularly useful for non-technical users handling large datasets (Biemer & Lyberg, 2003).
Automation in Data Cleaning: Taking Efficiency to New Heights
Manual data cleaning can be time-consuming, but automation can save hours while yielding more accurate results. As Schreiner, Riedl, and Roithmayr (2020) suggest, “Automation enhances the reliability of survey fraud detection.”
- Rule-Based Cleaning: Rule-based automation allows for setting specific criteria, such as removing responses completed in unusually short timeframes or containing excessive missing fields.
- Machine Learning for Anomaly Detection: Machine learning models, like isolation forests, can identify subtle fraud patterns (Schreiner, Riedl, & Roithmayr, 2020). These models enable the detection of outliers that manual checks might miss.
- Workflow Automation: Integrating data cleaning tools into a workflow automation system ensures a seamless transition from data collection to analysis. As Redmiles and Mazurek (2019) point out, “Workflow automation reduces human error, increasing efficiency.”
Impact of Data Cleaning on Survey Results
- Improved Accuracy and Reliability: With clean data, you can be confident that your survey results are both fraud-free and trustworthy. As highlighted by Wang and Strong (1996), detecting and removing suspicious responses ensures that the accuracy of your insights is significantly enhanced, enabling more meaningful conclusions.
- Boosted Efficiency and Cost Savings: According to Biemer and Lyberg (2003), automation in data cleaning not only improves the quality of results but also reduces the time and resources required for fraud detection. This makes the process more efficient and cost-effective for organizations dealing with large datasets.
- Enhanced Decision-Making: By investing in data cleaning, you lay the groundwork for better business decisions. Clean data leads to more accurate insights, as pointed out by Hill and Lewicki (2006), thereby improving the overall analytics process and enabling more informed decision-making based on reliable data.
Real-Life Success Stories: Data Cleaning in Action
Data cleaning is not just about removing errors; it’s about unlocking insights hidden beneath the noise. These two case studies showcase how effective data cleaning transformed inaccurate survey results into actionable business intelligence, allowing organizations to make smarter, data-driven decisions.
Case Study 1: Boosting Trust in E-commerce Surveys
Issue: EasyShop, a leading e-commerce platform, conducted a large-scale customer satisfaction survey. The company offered a $500 gift card as an incentive, which led to an overwhelming response of over 50,000 submissions within two weeks. However, anomalies were quickly detected—unusually fast completion times and identical response patterns raised suspicions of fraudulent entries, threatening the integrity of the survey results.
Challenges: The primary challenge EasyShop faced was identifying and differentiating genuine responses from fraudulent ones. As Wang and Strong (1996) point out, one of the main difficulties in large-scale surveys is managing fraud detection when incentives are involved, which often leads to:
- Repeated IP addresses
- Unnatural response patterns, such as identical answers across multiple surveys
- Extremely short completion times that indicate automated or dishonest responses
Solution: EasyShop implemented a multi-step data cleaning process. This included using fraud detection software that flagged repeated IP addresses and unusually fast responses. The company also manually reviewed a random sample of responses to confirm patterns of fraud. According to Biemer and Lyberg (2003), employing a combination of automated and manual cleaning methods ensures better accuracy in identifying fraudulent data.
Results: After applying these techniques, EasyShop was able to remove 18% of fraudulent responses. The cleaned dataset provided more reliable insights, allowing the company to make informed adjustments to its marketing strategy. As a result, customer engagement improved by 25%, showcasing the value of accurate survey data (Biemer & Lyberg, 2003).
Case Study 2: Political Poll Accuracy Restored
Issue: PoliticsPulse, a renowned polling firm, conducted a pre-election poll to predict voter preferences in swing states. However, after reviewing the data, the team discovered inconsistencies such as unusually uniform responses and submissions clustered within specific time frames. These issues suggested the possibility of survey fraud, which could potentially distort the accuracy of their polling results.
Challenges: One of the main challenges PoliticsPulse encountered was ensuring the integrity of the polling data. As Redmiles and Mazurek (2019) have noted, political polls are particularly vulnerable to fraudulent activity because of the high stakes involved. The firm faced several obstacles:
- Uniform response patterns that lacked variation, signaling bot activity
- Submissions with suspiciously similar time stamps, indicating potential automated responses
- Difficulty in filtering out fake respondents without losing genuine data
Solution: PoliticsPulse deployed advanced data cleaning tools that incorporated machine learning algorithms to detect suspicious patterns. According to Schreiner, Riedl, and Roithmayr (2020), using sophisticated data cleaning tools allows polling firms to identify and remove fraudulent responses more efficiently. The company also implemented time-based filters to identify submissions that were completed too quickly to be legitimate.
Results: Through these efforts, PoliticsPulse successfully removed 22% of fraudulent responses, significantly improving the accuracy of their poll results. The cleaned data allowed the firm to adjust their polling predictions, which closely matched the final election outcome. This restoration of accuracy boosted their reputation and increased client trust (Schreiner, Riedl, & Roithmayr, 2020).
Why Data Cleaning is Crucial for Accurate Survey Results
These real-world examples highlight the importance of data cleaning in ensuring survey accuracy and eliminating fraudulent entries. Whether you’re running a customer satisfaction survey or a political opinion poll, maintaining clean data is essential for producing reliable insights and making informed decisions.


